Manifest Settings
The manifest is the primary method to control parameters about your deployment: what it should be called, how big it should be, where it should be deployed to etc.
Datacenters
Given that not all resources may be available in all datacenters, Nelson understands that you may at times want to be picky about which particular datacenters you deploy your units into. With this in mind, Nelson supplies the ability to whitelist and blacklist certain datacenters.
datacenters:
only:
- portland
- redding
In this example, using only forms a whitelist. This would only deploy to our fictitious portland and redding datacenters.
datacenters:
except:
- seattle
Using the except keyword forms a blacklist, meaning that this deployment would deploy everywhere except in seattle. The common use case for this would be that seattle had not been upgraded to a particular bit of platform infrastructure etc.
Load Balancers
Load balancers are another top-level manifest declaration. For an overview of the LB functionality, see the routing page. LBs are first declared logically, with the following block:
loadbalancers:
- name: foo-lb
routes:
- name: foo
expose: default->8444/http
destination: foobar->default
- name: bar
expose: monitoring->8441/https
destination: foobar->monitoring
Next - just like units - you need to declare a plan in order to specify size and scale of the LB. Plans are discussed in-depth later in this reference, but here’s an example for completeness:
- name: lb-plan
instances:
desired: 4
Depending on the backend in use (e.g. AWS), various fields in the plan will be ignored, so be sure to check with your administrator which fields are required.
Namespaces
Namespaces represent virtual “worlds” within the shared computing cluster. From a manifest specification perspective, there are a few interesting things that Namespaces enable.
Committing
During a release event each unit will only be deployed into the default namespace (this is usually dev). After the initial release the unit can be deployed into other namespaces by “committing” it. This can be done via the commit endpoint of the API, or nelson unit commit in the CLI.
In an ideal world, whatever system you use for testing or validation, the user would integrate with the Nelson API so that applications can be automatically committed from namespace to namespace.
Plans
When deploying a unit in a given namespace, it is highly probable that the unit may require different resource capacity in each target namespace. For example, a unit in the dev namespace is unlikely to need the same resources that the same service in a high-scale production namespace would need. This is where plans come in, they define resource requirements, constraints, and environment variables.
Plan Specification
Plans define resource requirements, constraints, and environment variables, and are applied to units in a given namespace. Take the following example:
plans:
- name: dev-plan
cpu: 0.25
memory: 2048
- name: prod-plan
cpu: 1.0
memory: 8192
instances:
desired: 10
namespaces:
- name: dev
units:
- ref: foobar
plans:
- dev-plan
- name: qa
units:
- ref: foobar
plans:
- prod-plan
This example defines two plans: dev-plan and prod-plan. The fact that the words dev and prod are in the name is inconsequential, they could have been plan-a and plan-b. Notice that under the namespaces stanza each unit references a plan, this forms a contract between the unit, namespace, and plan. The example above can be expanded into the following deployments: the foobar unit deployed in the dev namespace using the dev-plan, and the foobar unit deployed in the production namespace using the prod-plan
As a quick note the memory field is expressed in megabytes, and the cpu field is expressed in number of cores (where 1.0 would equate to full usage of one CPU core, and 2.0 would require full usage of two cores). If no resources are specified Nelson will default to 0.5 CPU and 512 MB of memory.
Resource Requests and Limits
The resources specified by cpu and memory are generally treated as resource limits, or upper bounds on the amount of resources allocated per unit. Some schedulers, like Kubernetes, also support the notion of a resource request, or lower bound on the resources allocated. An example of this might be an application that requires some minimum amount of memory to avoid an out of memory error. For schedulers that support this feature, resource requests can be specified with a cpu_request and memory_request field in the same way cpu and memory are specified.
plans:
- name: dev-plan
memory_request: 256
memory: 512
In the event that a request is specified, a corresponding limit must be specified as well. For schedulers that support resource requests, if only a limit if specified then the request is set equal to the limit. For schedulers that do not support resource requests, requests are ignored and only the limits are used.
Deployment Matrix
In order to provide experimenting with different deployment configurations, Nelson allows a unit to reference multiple plans for a single namespace. Think of it as a deployment matrix with the form: units x plans. Use cases range from providing different environment variables (for S3 paths) to cpu / memory requirements. In the example below, the unit foobar will be deployed twice in the dev namespace, once with dev-plan-a and once with dev-plan-b.
plans:
- name: dev-plan-a
cpu: 0.5
memory: 256
environment:
- S3_PATH=some/path/in/s3
- name: dev-plan-b
cpu: 1.0
memory: 512
environment:
- S3_PATH=some/different/path/in/s3
namespaces:
- name: dev
units:
- ref: foobar
plans:
- dev-plan-a
- dev-plan-b
Environment Variables
Given that every unit is deployed as a container, it is highly likely that configuration may need to be tweaked for deployment into each environment. For example, in the dev namespace, you might want a DEBUG logging level, but in the production namespace you might only want ERROR level logging. To give a concrete example, let’s consider the popular logging library Logback, and a configuration snippet:
<?xml version="1.0" encoding="UTF-8"?>
<included>
<logger name="your.program" level="${CUSTOM_LOG_LEVEL}" />
</included>
In order to customize this log level on a per-namespace basis, one only needs to specify the environment variables under plans. Here’s an example:
plans:
- name: dev-plan
environment:
- CUSTOM_LOG_LEVEL=INFO
namespaces:
- name: dev
units:
- ref: foobar
plans:
- dev-plan
The .nelson.yml allows you to specify a dictionary of environment variables, so you can add as many as your application needs. Never, ever add credentials using this mechanism. Credentials or otherwise secret information should not be checked into your source repository in plain text.
Scaling
The plan section of the manifest is where users can specify the scale of deployment for a given unit. Consider the following example:
plans:
- name: default-foobar
cpu: 0.5
memory: 512
instances:
desired: 1
At the time of writing Nelson does not support auto-scaling. Instead, Nelson relies on “overprovisioned” applications and cost savings in a converged infrastructure where the scheduling sub-systems know how to handle over-subscription.
Health Checks
Health checks are defined at the service/port level, and multiple health checks can be defined for a single service/port. Health checks are used by Consul to determine the health of the service. All checks must be passing for a service to be considered healthy by Consul. Here’s an example of defining a health check in the manifest:
units:
- name: foobar
description: description for the foo service
ports:
- default->9000/http
plans:
- name: dev-plan
health_checks:
- name: http-status
port_reference: default
protocol: http
path: "/v1/status"
timeout: "10 seconds"
interval: "2 seconds"
namespaces:
- name: dev
units:
- ref: foobar
plans:
- dev-plan
In this example, the default port for the foobar service will have a http health check that queries the path /v1/status every 2 seconds in the dev namespace. Below is an explanation of each field in the health_checks stanza:
| Field | Description |
name |
An alphanumeric string that identifies the health check, it can contain alphanumeric characters and hyphens. |
port_reference |
Specifies the port reference which the service is running. This must match up with the port label defined in the ports stanza of `units`. |
protocol |
Specifies the protocol for the health check. Valid options are http, https, and tcp. |
path |
Specifies the path of the HTTP endpoint which Consul will query. The IP and port of the service will be automatically resolved so this is just the relative URL to the health check endpoint. This is required if protocol is http or https. |
timeout |
Specifies how long Consul will wait for a health check. It is specified like: "10 seconds". |
interval |
Specifies the frequency that Consul will perform the health check. It is specified like: "10 seconds". |
Traffic Shifting
Nelson has the ability to split traffic between two deployments when a new deployment is replacing an older one. A
traffic shift is defined in terms of a traffic shift policy and a duration. A traffic shift policy defines a function
which calculates the percentage of traffic the older and newer deployments should receive given the current moment in time.
As time progresses, the weights change and Nelson updates the values for the older and newer deployments. It should be
noted that it does not make sense to define a traffic shifting policy for a unit that is run periodically, i.e. define a
schedule. Nelson will return a validation error if a traffic shifting policy is defined for such a unit.
At the time of writing there are two traffic shift policies: linear and atomic. The linear policy is a simple function that shifts
traffic from the older version to the newer version linearly over the duration of the traffic shift. The atomic policy
shifts traffic all at once to the newer version.
Traffic shifts are defined on a plan as it is desirable to use different policies for different namespaces. For
example in the dev namespace one might want to define an atomic policy with a duration of 5 minutes, while in prod
the duration is 1 hour with a linear policy.
Below is an example of using traffic shifting:
units:
- name: foobar
description: description for the foo service
ports:
- default->9000/http
plans:
- name: dev-plan
traffic_shift:
policy: atomic
duration: "5 minutes"
- name: prod-plan
traffic_shift:
policy: linear
duration: "60 minutes"
namespaces:
- name: dev
units:
- ref: foobar
plans:
- dev-plan
- name: prod
units:
- ref: foobar
plans:
- prod-plan
Finally, Nelson provides a mechanism to reverse a traffic shift if it is observed that the newer version of the deployment is undesirable. Once a traffic shift reverse is issued, Nelson will begin to shift traffic back to the older deployment as defined by the traffic shifting policy. The reverse will shift traffic backwards until 100% is being routed to the older deployment. Once this happens the newer deployment will no longer receive traffic and will be eventually cleaned up by nelson. No other intervention is needed by the user after a reverse is issued.
Notifications
Nelson can notify you about your deployment results via Slack and/or email. Notifications are sent for a deployment when:
- a deployment has successfully completed or failed
- a deployment has been decommissioned
The following is a simple example that configures both email and Slack notifications:
notifications:
email:
recipients:
- greg@one.verizon.com
- tim@one.verizon.com
slack:
channels:
- infrastructure
- devops
Units
A “unit” is a generic, atomic item of work that Nelson will attempt to push through one of its workflows. Any given Unit represents something that can be deployed as a container with distinct parameters and requirements.
Ports
Units can be run either as a long-running process (service) or periodically (job). While services are meant to be long running processes, jobs are either something that needs to be run on a recurring schedule, or something that needs to be run once and forgotten about. Jobs are essentially the opposite of long-lived services; they are inherently short-lived, batch-style workloads.
Units that are meant to be long running typically expose a TCP port. A minimal example of a unit that exposes a port would be:
- name: foobar-service
description: description of foobar
ports:
- default->8080/http
This represents a single service, that exposes HTTP on port 8080. When declaring ports, the primary application port that is used for routing application traffic must be referred to as default. You can happily expose multiple ports, but only the default port will be used for automatic routing within the wider system. Any subsystem that wishes to use a non-default port can do so, but must handle any associated concerns. For example, one might expose a monitoring port that a specialized scheduler could call to collect metrics.
For completeness, here’s an example of a service unit that can be used in your .nelson.yml:
- name: foobar
description: description of foobar
workflow: magnetar
ports:
- default->8080/http
- other->7390/tcp
dependencies:
- ref: inventory@1.4
- ref: db-example@1.0
The ports dictionary items must follow a very specific structure - this is how Nelson expresses relationships in ports. Let’s break down the structure:
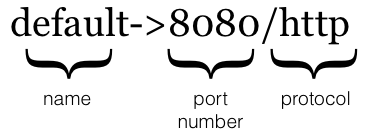 Figure 2.3.1: port definition syntax
Figure 2.3.1: port definition syntax
It’s fairly straight forward syntactically, but let’s clarify some of the semantics:
| Section | Description |
name |
Provides a canonical handle to a given port reference. For example, if your service exposes multiple ports then you may want to give the primary service port the name default whilst also exposing another port called monitoring. |
port number |
Actual port number that the container has EXPOSE'd at build time. |
protocol |
Wire protocol this port is using. Currently supported values are http, https or tcp. This information is largely informational, but may later be used for making routing decisions. |
Dependencies
For most units to be useful, it is very common to require another sub-system to successfully operate, and Nelson encodes this concept as dependencies. Dependencies need to be declared in the unit definition as a logical requirement:
- name: foobar-service
description: description of foobar
ports:
- default->8080/http
dependencies:
- ref: inventory@1.4
The unit name of the dependency can typically be discovered using the Nelson CLI command nelson units list, which will display the logical dependencies available in the specified datacenter. If you declare a dependency on a system, it must exist in every namespace you are attempting to deploy into; in the event this is not the case, Nelson will fail to validate your manifest definition.
Having multiple dependencies is common: typically a service or job might depend on a datastore, message queue or another service. Once declared in Nelson as a dependency, the appropriate Lighthouse data will also be pushed to the datacenter, which enables the user to dynamically resolve their dependencies within whatever datacenter the application was deployed into.
Resources
In addition to depending on internal elements like databases and message queues, any given units can also depend on external services (such as Amazon S3, Google search etc.) and are declared under the resources stanza. What makes resources different to dependencies is that they are explicitly global to the caller. Regardless of where you visit google.com from, you always access the same service from the caller’s perspective - the fact that google.com is globally distributed and co-located in many edge datacenters is entirely opaque.
resources block for external services. If the feature is abused for internal runtime systems, multi-region and data-locality will simply not work, and system QoS cannot be ensured.
A resource consists of a name and an optional description. While it is always useful to declare an external dependency, it is required if credential provisioning is needed (i.e. S3).
- name: foo
description: description of foobar
ports:
- default->8080/http
resources:
- name: s3
description: image storage
All resources must define a uri associated with it. Because a uri can be different between namespaces it is defined under the plans stanza. For example, one might use one S3 bucket for qa and another for dev.
plans:
- name: dev
resources:
- ref: s3
uri: s3://dev-bucket.organization.com
- name: qa
resources:
- ref: s3
uri: s3://qa-bucket.orgnization.com
Schedules
Units that are meant to be run periodically define a schedule under the plans stanza. They can also optionally declare ports and dependencies. The example below will be run daily in dev and hourly in prod.
units:
- name: foobar-batch
description: description of foobar
dependencies:
- ref: inventory@1.4
plans:
- name: dev
schedule: daily
- name: prod
schedule: hourly
namespaces:
- name: dev
units:
- ref: foobar-batch
plans:
- dev-plan
- name: prod
units:
- ref: foobar-batch
plans:
- prod-plan
Possible values for schedule are: monthly, daily, hourly, quarter-hourly, and once. These values can be mapped to the following cron expressions:
monthly -> 0 0 1 * *
daily -> 0 0 * * *
hourly -> 0 * * * *
quarter-hourly -> */15 * * * *
The value once is a special case and indicates that the job will only be run once. If more control over a job’s schedule is needed the schedule field can be defined directly with any valid cron expression.
plans:
- name: dev
schedule: "*/30 * * * *"
The more powerful cron expression is typically useful when you require a job to run at a specific point in the day, perhaps to match a business schedule or similar.
Workflows
Workflows are a core concept in Nelson: they represent the sequence of actions that should be conducted for a single deployment unit. Whilst users cannot define their own workflows in an arbitrary fashion, each and every unit has the chance to reference an alternative workflow by its name. The magnetar workflow first replicates the required container to the target datacenter, and then attempts to launch the unit using the datacenters pre-configured scheduler. Broadly speaking this should be sufficient for the majority of deployable units.
Additionally, there are the canopus and pulsar workflows. The canopus workflow simply deploys and deletes units. Vault and traffic shifting support is not yet supported. The pulsar workflow also deploys and deletes units, but has additional support for provisioning authentication roles in Vault for use by Kubernetes pods at runtime.
If users require a specialized workflow, please contact the Nelson team to discuss your requirements.
Expiration Policies
Nelson manages the entire deployment lifecycle including cleanup. Deployment cleanup is triggered via the deployments expiration date which is managed by the expiration_policy field in the plans stanza. The expiration_policy field defines rules about when a deployment can be decommissioned. Below is a list of available expiration policies:
| Reference | Description |
retain-active |
Retain active is the default expiration policy for services. It retains all versions with an active incoming dependency. |
retain-latest |
Retain latest is the default expiration policy for jobs. It retains the latest version. |
retain-latest-two-major |
Retain latest two major is an alternative policy for jobs. It retains latest two major versions, i.e. 2.X.X and 1.X.X. |
retain-latest-two-feature |
Retain latest two feature is an alternative policy for jobs. It retains the latest two feature versions, i.e. 2.3.X and 2.2.X. |
Nelson does not support manual cleanup, by design. All deployed stacks exist on borrowed time, and will eventually expire. If you do not explicitly choose an expiration policy (this is common), then Nelson will apply some sane defaults, as described in the preceding table.
Meta Tags
Sometimes you might want to “tag” a unit with a given set of meta data so that later you can apply some organization-specific auditing or fiscal tracking program. In order to do this, Nelson allows you to tag - or label - your units. Here’s an example:
units:
- name: example
description: example
ports:
- default->9000/http
meta:
- foobar
- buzzfiz
Meta tags may not be longer than 14 characters in length and can only use characters that are acceptable in a DNS name.
Alerting
Alerting is defined per unit, and then deployed for each stack that is created for that unit. Nelson is not tied to a particular alerting system, and as with the integrations with the cluster managers, Nelson can support integration with multiple monitoring and alerting backends. At the time of writing, Nelson only supports Prometheus as a first-class citizen. This is a popular monitoring and alerting tool, with good throughput performance that should scale for the majority of use cases.
From a design perspective, Nelson is decoupled from the actual runtime, and is not in the “hot path” for alerting. Instead, Nelson acts as a facilitator and will write out the specified alerting rules to keys in Consul for the datacenter in question. In turn, it is expected that the operators have setup consul-template (or similar) to respond to the update of the relevant keys, and write out the appropriate configuration file. In this way, Nelson delegates the actual communication / implementation of how the rules are ingested to datacenter operations.
The following conventions are observed when dealing with alerts:
- Alerts are always defined for a particular unit.
- All alerts are applied to the unit in any namespace, except those specified by opt-outs in the plan.
- Notification rules must reference pre-existing notification groups, which are typically configured by your systems administrator, based on organizational requirements.
Let’s consider an example, that expands on the earlier explanations of the unit syntax:
---
units:
- name: foobar
description: >
description of foobar
ports:
- default->8080/http
alerting:
prometheus:
alerts:
- alert: instance_down
expression: >-
IF up == 0
FOR 5m
LABELS { severity = "page" }
ANNOTATIONS {
summary = "Instance {{ $labels.instance }} down",
description = "{{ $labels.instance }} of job {{ $labels.job }} down for 5 minutes.",
}
rules:
- rule: "job_service:rpc_durations_microseconds_count:avg_rate5m"
expression: "avg(rate(rpc_durations_microseconds_count[5m])) by (job, service)"
The observant reader will notice the alerting.prometheus dictionary that has been added. When using the support for Prometheus, Nelson allows you to specify the native Prometheus alert definition syntax inline with the rest of your manifest. You can use any valid Prometheus alert syntax, and the alert definitions will be automatically validated using the Prometheus binary before being accepted by Nelson.
Whilst the alerting support directly exposes an underlying integration to the user-facing manifest API, we made the choice to expose the complete power of the underlying alerting system, simply because the use cases for monitoring are extremely varied, and having Nelson attempt to “translate” arbitrary syntax for a third-party monitoring system seems tedious and low value. We’re happy with this trade off overall as organizations change their monitoring infrastructure infrequently, so whilst it’s a “moving target” over time, it is slow moving.
Alert Syntax
Upon first glance, the alert block in the manifest can seem confusing. Thankfully, there are only three sections a user needs to care about. The table below outlines the alert definitions.
| Dictionary | Description |
prometheus.alerts |
An array of alert rules for your unit. An alert rule is split into two keys: the alert and the expression. |
prometheus.alerts[...].alert |
The name of the alert. This alert name is used as a key for opt-outs and appears throughout the alerting system. Select a name that will make sense to you when you get paged at 3am. The alert name should be in snake case and must be unique within the unit. Valid characters are [A-Za-z0-9_]. |
prometheus.alerts[...].expression |
Prometheus expression that defines the alert rule. An alert expression always begins with `IF`. Please see the Prometheus documentation for a full discussion of the expression syntax. We impose the further constraint that all alert expressions come with at least one annotation.. |
Rule Syntax
In addition to specification of alerts, the manifest also allows for the specification of Prometheus rules. See the Prometheus documentation on recording rules for a discussion on the differences between alerts and recording rules.
| Dictionary | Description |
prometheus.rules |
An array of recording rules for your unit. Recording rules pre-calculate more complicated, expensive expressions for use in your alerting rules. Like alert rules, each recording rule is split into two keys: rule and expression. |
prometheus.rules[...].rule |
Name of the recording rule. It should be in snake case and unique within the unit. Valid characters are [A-Za-z0-9_]. |
prometheus.rules[...].expression |
Prometheus expression that defines the recording rule. See the documentation for the Prometheus query language to get an overview of what sort of expressions are possible. |
Opting Out
A good alert is an actionable alert. In some cases, an alert may not be actionable in a given namespace. A development team might know that quirks in test data in the qa namespace result in high request latencies, and any alerts on such are not informative. In this case, one may opt out via the alert_opt_outs array for the unit.
units:
- name: foobar
description: >
description of foobar
ports:
- default->8080/http
dependencies:
- ref: cassandra@1.0
alerting:
prometheus:
alerts:
- alert: api_high_request_latency
expression: >-
IF ...
plans:
- name: qa-plan
cpu: 0.13
memory: 2048
alert_opt_outs:
- api_high_request_latency
- name: prod-plan
cpu: 0.65
memory: 2048
namespaces:
- name: qa
units:
- ref: foobar
plans:
- qa-plan
- name: production
units:
- ref: foobar
plans:
- prod-plan
In the above example, the api_high_request_latency alert for the foobar unit is opted out in the qa namespace. The alert will still fire in dev and prod namespaces. A key in the alert_opt_outs array must refer to an alert key under alerting.prometheus.alerts in the corresponding unit, otherwise Nelson will raise a validation error when trying to parse the supplied manifest.